| 使用python统计《红楼梦》中人物出现的次数 | 您所在的位置:网站首页 › Taco Wednesday! › 使用python统计《红楼梦》中人物出现的次数 |
使用python统计《红楼梦》中人物出现的次数
|
1、安装jieba第三方库 jieba库是优秀的中文分词库,它能够将句子分成词语。 安装方法: 在cmd命令行中输入:pip install jieba 电脑在联网的情况下会自动下载安装jieba库 2、程序代码: #XiyoujiV1.py import jieba txt = open(‘redstone.txt’, ‘r’, encoding = ‘utf-8’).read() #读取txt文件 words = jieba.lcut(txt) #使用jieba库进行精确模式分词,返回一个列表类型的分析结果 counts = {} #创建字典数据类型 for word in words: #统计词出现的次数 if len(word) == 1: continue else: counts[word] = counts.get(word,0)+1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(15): #输出出现次数较多的前15个人物 word, count = items[i] print("{0:5}".format(word, count)) 3、下载红楼梦的文本文档,保存为.txt格式 4、运行程序后出现了如下错误提示: 5、进一步优化 结果中一个、什么、我们并不是人名,我们需要去除。因此,我们对结果进一步统一优化。 #CalThreeKingdomsV1.py import jieba txt = open(‘redstone.txt’, ‘r’, encoding = ‘utf-8’).read() excludes = {‘什么’, ‘一个’, ‘我们’, ‘你们’, ‘如今’, ‘说道’, ‘知道’, ‘起来’, ‘这里’,‘姑娘’,‘出来’,‘众人’,‘那里’,‘自己’} words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue elif word == ‘贾母’ or word == ‘老太太’: rword = ‘贾母’ else: rword = word counts[word] = counts.get(word,0)+1 for word in excludes: del counts[word] items = list(counts.items()) items.sort(key = lambda x:x[1], reverse=True) for i in range(10): word, count = items[i] print("{0:5}".format(word, count)) 6、运行的结果如下: 7、总结: txt文档的存储为容易出错的地方,需要注意! 后期的优化,需要不断剔除其他干扰词汇。同样使用该方法可以统计西游记、水浒传、三国中的人物出场次数! |
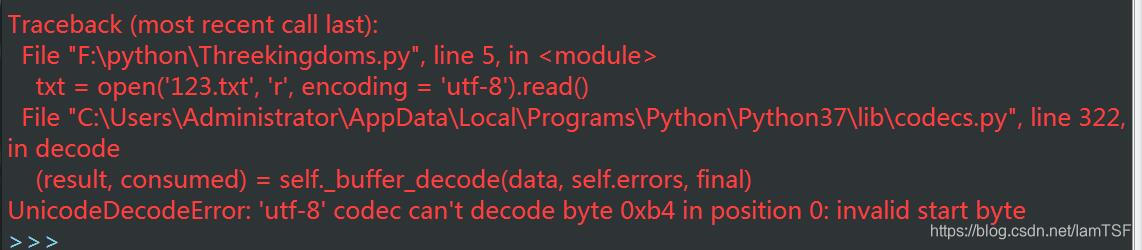 这里的错误是由于txt文档的保存格式不对,默认情况下txt文档的编码为ANSI格式,而此处为udf-8读取方式,所以会出现以上的错误提示。
这里的错误是由于txt文档的保存格式不对,默认情况下txt文档的编码为ANSI格式,而此处为udf-8读取方式,所以会出现以上的错误提示。 
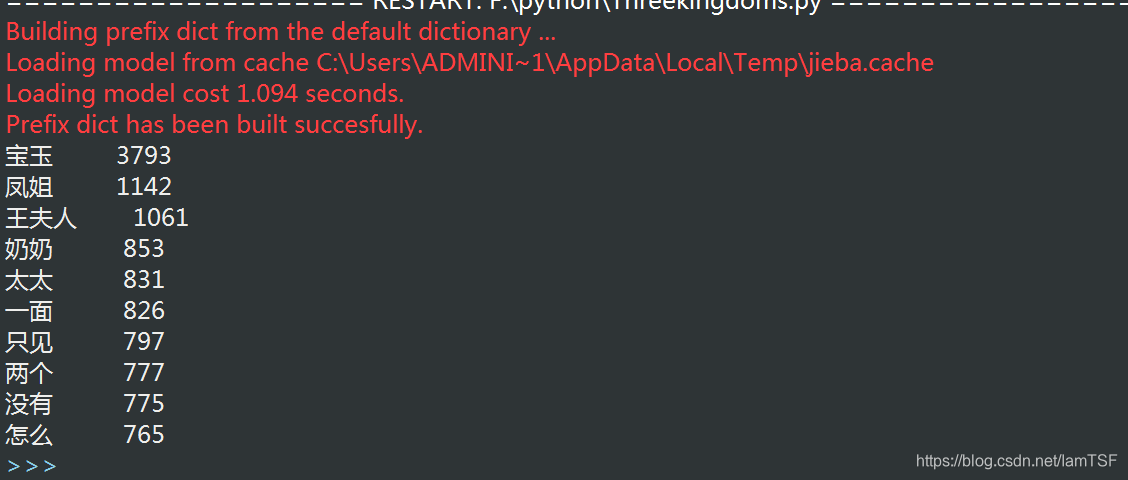
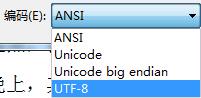 需要在txt保存时另存为中,编码下拉框中选择UTF-8。 此时,再次运行程序即可。 运行成功后的结果如下图:
需要在txt保存时另存为中,编码下拉框中选择UTF-8。 此时,再次运行程序即可。 运行成功后的结果如下图: 
【本文地址】